The 57% Hallucination Rate in LLMs: A Call for Better AI Evaluation
Author: Max Milititski
Introduction
Large Language Models (LLMs) are rapidly evolving, pushing the boundaries of what AI can achieve. However, the traditional methods used to evaluate their capabilities are struggling to keep pace with this rapid advancement. Here’s why traditional LLM evaluation methods are falling short:
Limited Scope: Traditional methods often focus on narrow metrics like perplexity or BLEU score. These metrics primarily assess an LLM’s ability to mimic existing text patterns, neglecting its broader capabilities in areas like reasoning, knowledge application, and creative problem-solving.
Black Box Intransparency: Traditional methods often fail to provide insights into the internal workings of an LLM. This lack of transparency makes it difficult to understand how the model arrives at its outputs, hindering efforts to improve its performance and identify potential biases.
Data Dependence: Many traditional methods rely heavily on curated benchmark datasets. These datasets may not fully reflect the real-world complexities and nuances that LLMs encounter in diverse applications. This can lead to models that perform well on benchmarks but struggle with real-world task
Insights from the Intuit Webinar: Evaluating LLMs for Your Use Case: Unleash the Power of Large Language Models.
The ever-evolving world of AI demands a new approach to Large Language Model (LLM) evaluation. Traditional methods struggle to keep pace with the growing capabilities of these AI marvels.
Last month Intuit webinar provided profound insights into the strategic evaluation of Large Language Models (LLMs). The discussion emphasized that the true potential of these AI powerhouses can only be unlocked through meticulous and tailored evaluations. Experts shared that understanding the specific needs and nuances of each use case is crucial in determining the effectiveness of an LLM.
They stressed the importance of not just evaluating an LLM based on general metrics but also on how well it performs in specific scenarios that mirror real-world applications.
In the webinar, 3 Popular Methods for Evaluation were discussed
Evaluating LLMs effectively can feel like navigating a maze. Here are 3 prevalent methods, each with its limitations:
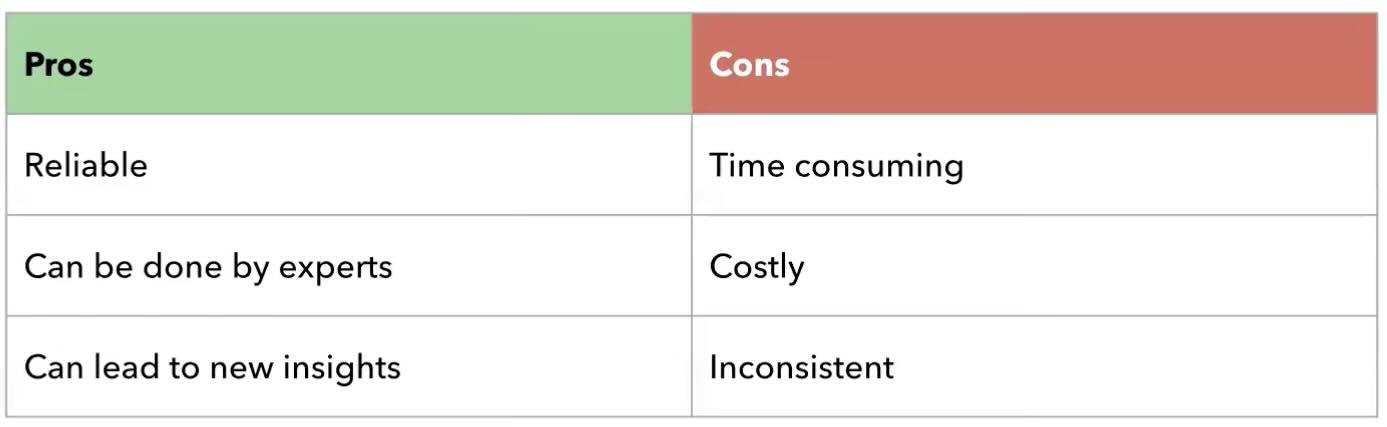
Manual Examination: This traditional approach involves humans directly examining the LLM’s responses according to predefined criterias. While offering valuable insights, it can be time-consuming, subjective, and difficult to scale for large-scale evaluations.
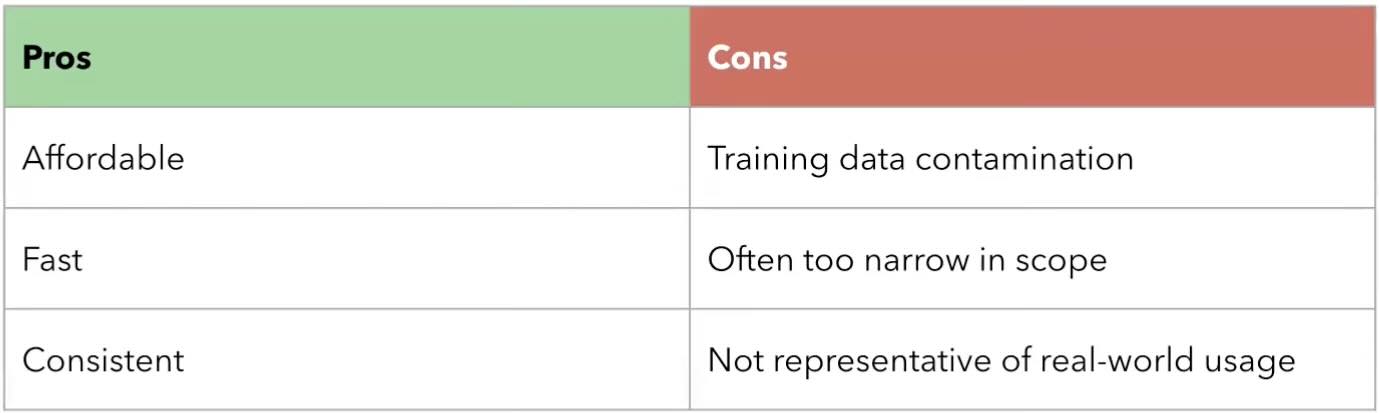
Automatic Tests: Creating automated tests can streamline the evaluation process. These tests can assess specific criterias like factual accuracy or adherence to style guidelines. However, developing comprehensive test suites can be complex, and automatic tests may miss nuances that human judgments can capture.
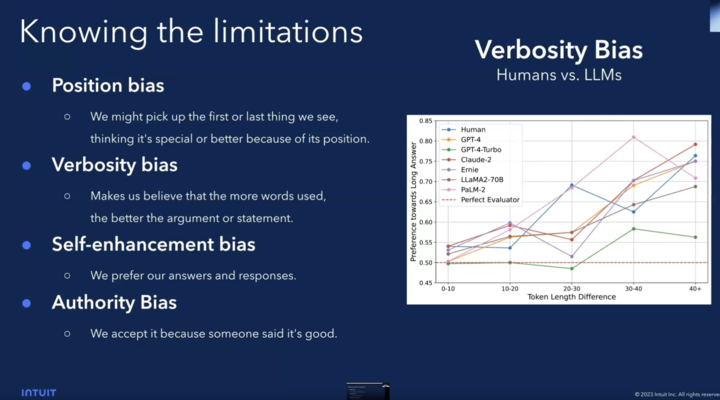
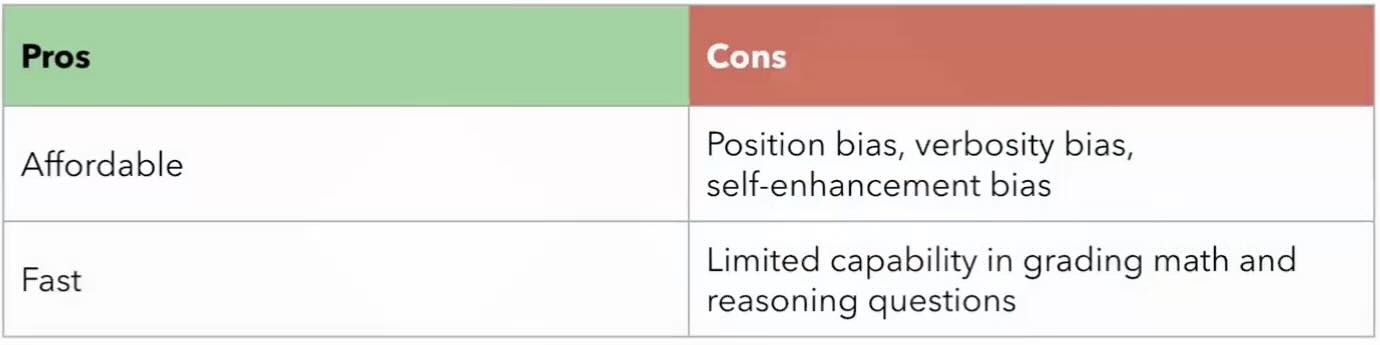
LLM-as-a-Judge: This emerging approach utilizes one LLM to evaluate another. While intriguing, it relies on the accuracy and bias of the judging LLM. Additionally, developing evaluation criteria for this approach can be challenging.
We see that LLM judges have biases and humans too, at Tasq.ai we believe that it’s much more problematic with LLM and that we can overpass the human bias (https://www.tasq.ai/responsible-ai/)
Conclusion:
In the rapidly advancing field of AI, the effectiveness of your LLMs hinges on their ability to produce results that are not only accurate and unbiased but also culturally attuned.
At Tasq.ai, we are offering a new approach for LLM evaluation and are committed to pushing the boundaries of AI evaluation to ensure your models are truly fit for their intended purposes. Our approach integrates advanced technology with a human-in-the-loop system, combining cutting-edge AI capabilities with invaluable human insights.
This synergy ensures that every evaluation is as robust and comprehensive as possible. Are you ready to transform your LLM evaluation process? Contact Tasq.ai today and learn how our unique blend of technology and human expertise can help your AI initiatives achieve unparalleled success.
Latest Must-Reads From Tasq.ai
Unveiling the Best GenAI Model for Retail: A Comparative Study Using Tasq.ai’s Eval Genie
Tasq.ai's Eval Genie offers a comprehensive comparative study to guide retailers in making informed decisions.